Fleurissement Optimizer — comment construire un outil IA pour guider l'astreinte le weekend
Article technique — suite de "Quand un problème de fleurissement devient un projet d'entreprise"
Le groupe de travail avait résolu les problèmes techniques les plus visibles. Les étuves avaient été recalibrées, les règles d'affectation produit-étuve établies. Mais il restait un angle mort : le weekend.
Le personnel d'astreinte pouvait venir de n'importe quel service. Face à une étuve anormale un samedi matin, la décision à prendre est lourde — une mauvaise baisse du pH, c'est un risque bactériologique et 45 000 € de saucissons perdus. Les astreinteurs expérimentés étaient appelés plusieurs fois par weekend. La responsable maintenance aussi. Ce n'était pas tenable.
La question était : peut-on construire un outil qui guide quelqu'un qui ne connaît pas le fleurissement, sur son téléphone, dans une étuve ?
Prototyper d'abord
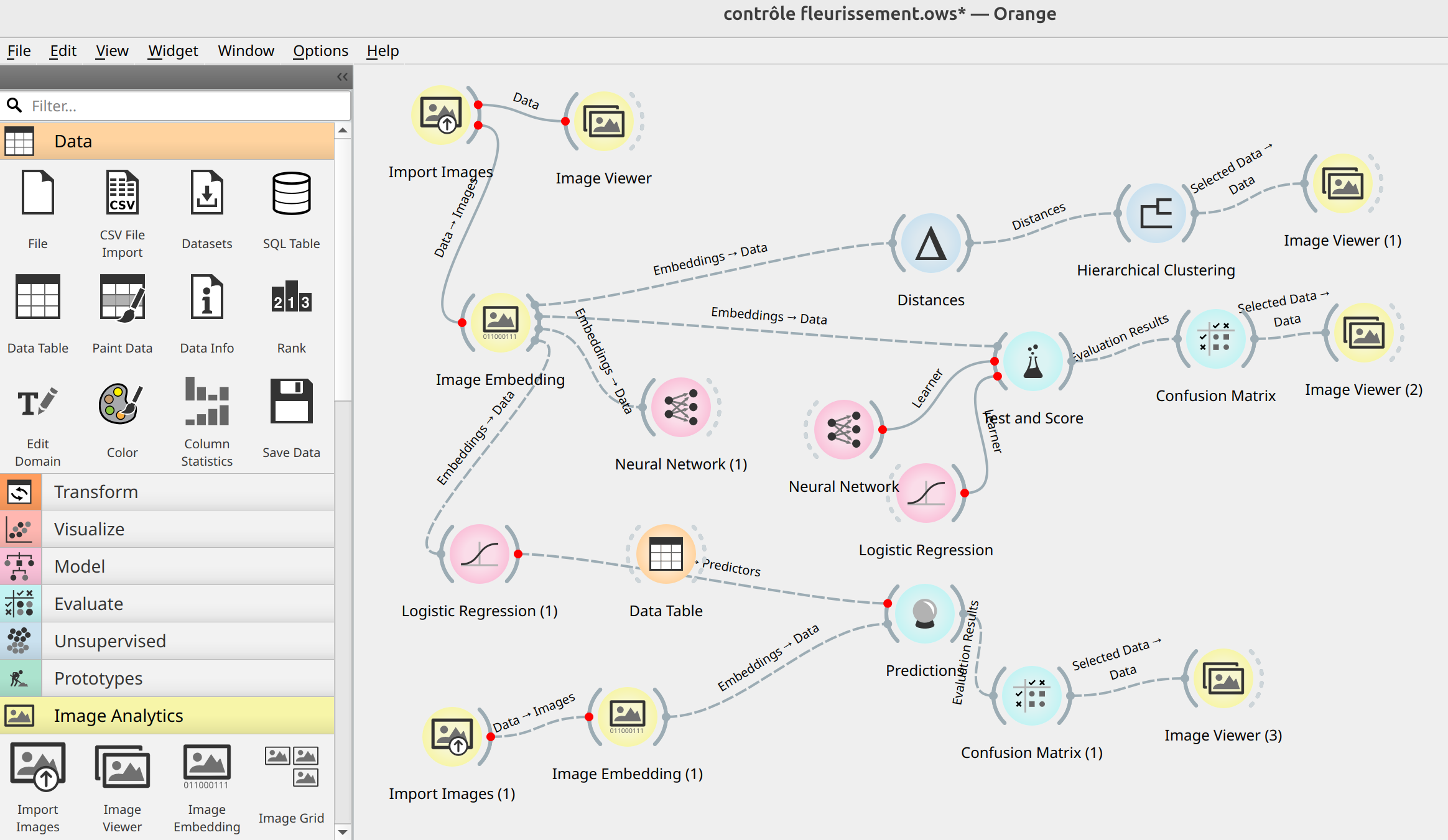
Avant d'écrire une ligne de Django, j'ai ouvert Orange Data Mining. ODM est un outil de data science visuel — on assemble des workflows en glissant-déposant des blocs, sans coder. L'objectif n'était pas de construire le logiciel. C'était de savoir si la reconnaissance visuelle des stades de fleurissement était faisable.
En 20 minutes, un premier workflow tournait. Les embeddings se calculaient pendant la pause déjeuner. J'ai testé tous les modèles de vision disponibles dans ODM : SqueezeNet, VGG-16, VGG-19, Painters, DeepLoc, OpenFace, InceptionV3. La vraie difficulté n'était pas le choix du modèle de vision — c'était de décider entre réseau neuronal et régression logistique pour la classification finale. ODM permet de comparer les deux en deux clics, matrices de confusion à l'appui. La régression logistique couplée à InceptionV3 a gagné — plus rapide, plus interprétable, suffisamment précise pour le cas d'usage.
Définir ce qui est connu
Au départ j'avais 8 stades de fleurissement — c'est ce qui est observable sur le terrain. J'ai fini à 5. Les stades 1 et 5 sont simples : pas fleuri du tout, trop fleuri. Les stades 2, 3, 4 sont éphémères — trop peu de photos disponibles, et certaines sont à cheval entre deux stades.
J'ai annoté 740 photos moi-même — en général pendant les réunions. Me focaliser sur quelque chose me permet de mieux écouter. C'était plus productif que de gribouiller mon bloc-note.
La grande variabilité visuelle du stade 1 a été le problème le plus difficile. Un saucisson nature est très rouge au stade 1. Un saucisson à l'emmental est presque blanc. Le modèle doit comprendre que ces deux aspects très différents correspondent au même stade — pas encore fleuri. L'augmentation de données sur les classes minoritaires (stades 2, 3, 4) a partiellement compensé le manque de photos terrain.
Le problème du téléphone
InceptionV3 analyse des images en 299x299 pixels. Sur une photo de téléphone d'astreinte — qualité médiocre, éclairage très blanc, murs blancs en arrière-plan — les détails sont écrasés. Un mur blanc mal cadré donnait un stade 5. Un reflet sur des saucissons pas encore fleuris donnait aussi un stade 5.
La solution : découper chaque image en grille 5x5 — 25 zones analysées indépendamment. J'ai testé 4x4 (pas suffisant), 6x6 (trop lourd et trop lent). Le 5x5 était le bon compromis. C'était aussi une façon de zoomer — chaque patch représente une zone précise de l'étuve, pas l'image entière.
Les zones identifiées comme sol, mur ou balancelle sont exclues du calcul. Le résultat affiché n'est pas une classe unique mais une distribution — "Stade 5 : 72%, Stade 4 : 18%, Stade 3 : 10%" — avec une alerte si la confiance sur le stade dominant passe sous 70%.
Avant même l'analyse, 5 tests de qualité photo sont effectués : luminosité, surexposition, puits de lumière, reflets, flou. Si la photo est inexploitable, un message d'erreur avec conseil s'affiche. L'astreinteur reprend la photo dans de meilleures conditions.
D'ODM à Django
Le passage d'ODM à Django a été moins difficile qu'on pourrait le croire. InceptionV3 sur ODM, c'est InceptionV3 sur Django — les mêmes briques, la même logique. Au lieu d'assembler des widgets visuels, on assemble des blocs de code Python.
La vraie richesse de Django c'est ailleurs : la séparation modèle / formulaire / vue / template permet de construire des interfaces très différentes selon l'utilisateur. Une vue terrain optimisée mobile pour l'astreinteur dans l'étuve. Une vue analyse sur PC pour le maître fleurisseur qui valide les prédictions et enrichit le dataset. Le côté open source et collaboratif permet d'itérer rapidement sans dépendance à un éditeur.
Les règles métier — la partie impossible à coder seul
Le logiciel génère une recommandation en fonction de trois paramètres : le stade détecté, la phase d'étuvage en cours (1 à 10), et le temps restant dans la phase. La logique est précise — en phase 8, si le stade est 1 ou 2 avec suffisamment de temps restant, on attend. Si le stade est 3, 4 ou 5, on passe en phase 9.
Ces règles, c'est le chef d'atelier qui les a dictées. Moi je les ai codées.
Et c'est là le point essentiel : rien de tout ça n'aurait été possible si le groupe de travail n'avait pas existé avant. Si les étuves n'avaient pas été recalibrées. Si les règles d'affectation produit-étuve n'avaient pas été établies. Si la maintenance n'avait pas trouvé le composant électrique de l'étuve 14.
L'IA ne résout rien si l'amont n'est pas cadré auparavant.
Fleurissement Optimizer est disponible en démonstration sur rendez-vous — contact@optimizer-labs.fr